Link to the dataset : https://hf.co/datasets/LabHC/histoires_morales.Link for the paper : https://arxiv.org/abs/2501.17117.Code : https://github.com/upunaprosk/histoires-morales
TL;DR We create and release FrenchToxicityPromptsLink to the dataset : https://download.europe.naverlabs.com/FrenchToxicityPrompts/.Link for the paper : https://aclanthology.org/2024.trac-1.12/.
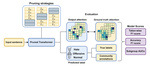
TL;DR We investigate the impact of LLM compression on three aspects within QA tasks: (i) model confidences, (ii) calibration error, and (iii) predictive entropy.Link for the paper : https://arxiv.org/abs/2405.00632.
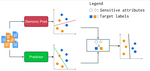
TL;DR We propose a novel approach to mitigate bias in text encoders, that aims to tackle bias directly in the latent space on which documents are projected, making our model applicable to any text encoder or decoder.
Link for the paper : https://aclanthology.org/2023.emnlp-main.978/.
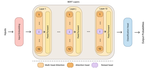
TL;DR We offer empirical insights into bias investigation within the inner layers and heads of BERT and compare these findings with results obtained from DistilBERT.
Link for the paper : https://link.springer.com/chapter/10.1007/978-3-031-30047-9_20.
TL;DR We analyse the layers’ contribution to rational model decision-making in terms of performance and fairness.
Link for the paper : https://hal.science/hal-04104840/document.
TL;DR We introduce SMaLL-100, a distilled version of the M2M100 (12B) model, a massively multilingual machine translation model covering 100 languages.
Link for the paper : https://arxiv.org/abs/2210.11621.
TL;DR We show in this article that the compression of M2M-100 amplifies biases and hurts under-represented languages.
Link for the paper : https://arxiv.org/abs/2205.10828.