Our paper “What Do Compressed Multilingual MT Models Forget?” is accepted to EMNLP 2022
TL;DR We show in this article that the compression of M2M-100 amplifies biases and hurts under-represented languages.
Link for the paper : https://arxiv.org/abs/2205.10828.
Over the recent years, pre-trained Transformer models have reached a substantial improvement in a variety of Natural Language Processing tasks. This improvement mostly comes from increasing their parameter size which escalates the cost of training, and hurts the memory footprint and latency at inference.
Specially in Neural Machine Translation (NMT) task, massively MNMT models demonstrated promising results. They have been shown particularly interesting for low-resource languages which benefit a lot from knowledge transfer. On the other hand, it has also been observed that the curse of multilinguality may hurt the performance in high-resource languages. The strategy employed to overcome this problem is to scale up the number of parameters, thus attaining state-of-the-art performance in both high and low-resource languages.
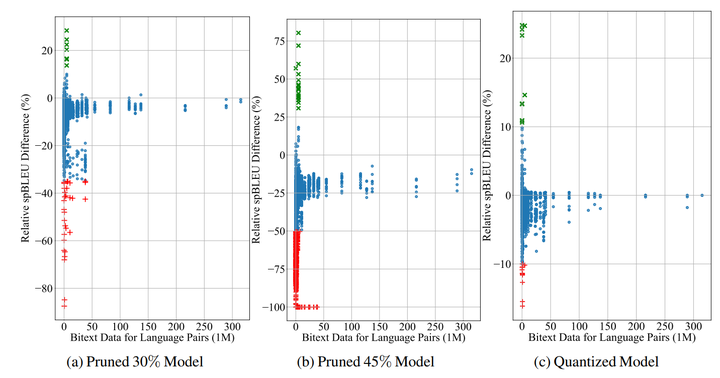
Consequently, efficient inference with these very large models has become a crucial problem. This challenge can be overcome through model compression, e.g. knowledge distillation, pruning, and quantization. These methods can be applied with a little loss in top-line metrics, while reducing the memory-footprint, and enhancing inference time. However, recent work has demonstrated that under-represented features can suffer from a drastic decrease in performance which is not necessarily reflected by global (aggregated) metrics.
In multilingual NMT, the overall metrics are often reported as an average across all the language pairs, where the performance between individual language pairs can vary a lot. Therefore it is even more critical to understand what would be the exact impact of compression on multilingual NMT models, beyond the aggregated metrics.
In this work, we illustrate the impacts of applying compression methods to massively multilingual NMT models, that are pre-trained in a great number of languages in several domains. In this study, we concentrate on light compression techniques, specifically post-training quantization and magnitude pruning without any further finetuning.
We exploit the recent and largest MNMT model, M2M-100, that covers 100 languages and contains nearly 12B parameters and analyze the impact of compression on different language pairs evaluated on FLORES-101 benchmark covering 101 languages.
Our contributions are as follows:
- We conduct extensive analysis on the effects of light compression methods for massively multilingual NMT models.
- On FLORES-101, we discover that while the overall performance is barely impacted by the compression, a subset of language pairs corresponding to under-represented languages during training suffers an extreme drop in performance.
- Also, we observe an important improvement for some language pairs after the compression. We hypothesize that this is due to the removal of noisy memorization.
- We show that the compression amplifies gender and semantic biases, hidden in MNMT models across several high-resource languages by evaluating on MT-Gender, and DiBiMT benchmarks.
Christophe Gravier
Professor of Computer Science, Head of Télécom Saint-Etienne
Scientific Coordinator of the Diké Project