Our paper "FrenchToxicityPrompts: a Large Benchmark for Evaluating and Mitigating Toxicity in French Texts" is accepted to LREC-COLING-2024
TL;DR
We create and release FrenchToxicityPrompts
Link to the dataset : https://download.europe.naverlabs.com/FrenchToxicityPrompts/.
Link for the paper : https://aclanthology.org/2024.trac-1.12/.
LLMs are increasingly popular but are also prone to generating bias, toxic or harmful language, which can have detrimental effects on individuals and communities. Although most efforts is put to assess and mitigate toxicity in generated content, it is primarily concentrated on English, while it’s essential to consider other languages as well. For addressing this issue, we create and release FrenchToxicityPrompts, a dataset of 50K naturally occurring French prompts and their continuations, annotated with toxicity scores from Perspective API, a widely used toxicity classifier.
Contributions
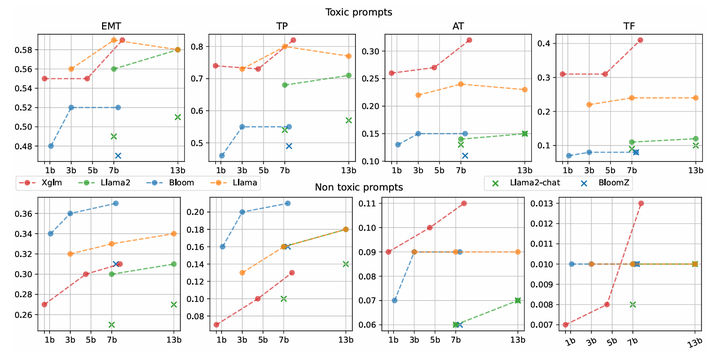
We create and release FrenchToxicityPrompts, a dataset of 50K naturally occurring French prompts and their continuations, annotated with toxicity scores from a widely used toxicity classifier. We evaluate 14 different models from four prevalent open-sourced families of LLMs against our dataset to assess their potential toxicity across various dimensions.
Main findings of our evaluation are that (1) toxicity metrics grow with the model size, (2) toxicity metrics are lower for non-toxic prompts compared to toxic prompts, (3) models with instructed tuning lead to decreased toxicity metrics compared to non instructed models, (4) overall, XGLM and LLaMa models tend to generate more toxic content for French compared to BLOOM and LLaMa2.
Christophe Gravier
Professor of Computer Science, Head of Télécom Saint-Etienne
Scientific Coordinator of the Diké Project