Our paper "Fair Text Classification with Wasserstein Independence" is accepted to EMNLP 2023
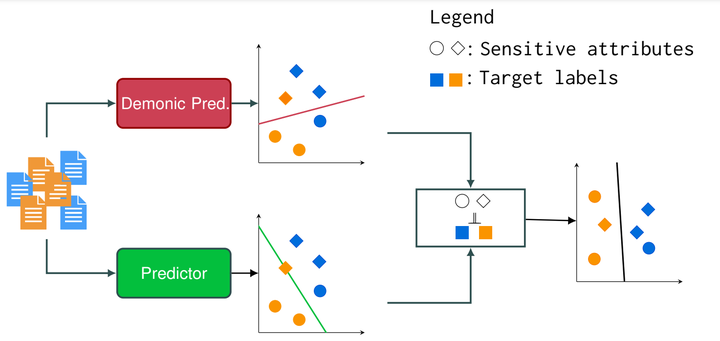
TL;DR We propose a novel approach to mitigate bias in text encoders, that aims to tackle bias directly in the latent space on which documents are projected, making our model applicable to any text encoder or decoder.
Link for the paper : https://aclanthology.org/2023.emnlp-main.978/.
Machine learning algorithms have become increasingly influential in decision-making processes that significantly impact our daily lives. One of the major challenges that has emerged in research, both academic and industrial, concerns the fairness of these models, i.e. their ability to prevent predictions related to individuals to be based on sensitive attributes such as gender or ethnicity.
In this article, we focus on the problem of fairness in the domain of Natural Language Processing (NLP). While many studies already report biases in NLP systems, these issues become even more significant with the advent of public-ready AI-powered NLP systems such as ChatGPT (OpenAI) or Google Bard (Pichai), making the need for fair NLP solutions even more compelling.As more researchers work to overcome these shortcomings, the first problem is to define what fairness is. Such a definition may hardly be consensual or is at least difficult to establish, as it depends on situational and cultural contexts.
In this work, we adopt the most common definition of group fairness, and the one adopted by laws in several countries, which is based on the notion of disparate impact: a prediction model is considered to have a disparate impact if its results disproportionately harm (or benefit) people with certain sensitive attribute values. In this work, we focus on group fairness for neural text classification as it is one of the most ubiquitous tasks in our society, with prominent examples in medical and legal domains or human resources, to name a few.
Neural text classification relies on text encoders, which are parameterized and learned functions that map tokens (arbitrary text chunks) into a latent space of controllable dimension, usually followed by a classification layer. Built upon the Transformers architecture, popular Pre-trained Language Models (PLMs) such as BERT, GPT3 or Llama leverage self-supervised learning to train the text encoder parameters.
In modern NLP pipelines, these PLMs are further fine-tuned on the supervised task at hand. Ultimately, PLMs accumulate uncontrolled levels of unfairness due to unbalanced learning data or algorithmic biases, for instance. This results in observable biases in predictions but also in the latent space.
Contributions
We propose a novel approach (see Figure above), to mitigate bias in text encoders, that aims to tackle bias directly in the latent space on which documents are projected, thus making our model applicable to any text encoder or decoder (e.g. BERT or LLAMA).
To proceed, we disentangle the neural signals encoding bias from the neural signals used for prediction. The proposed architecture is based on three components. First, two Multi-Layer Perceptrons (MLPs): the first one whose objective is to predict the sensitive attribute, and the second one is dedicated to the prediction task at hand. Then, a third MLP, referred to as a critic, approximates the Wasserstein distance that acts as a regularizer in our objective function.
Our proposition overcomes a major shortcoming of prior studies: they rely on the availability of the sensitive attributes at train time. A constraint that is incompatible with recent regulations as the new European ones, that enforce more stringent requirements for the collection and utilization of protected attributes.
Prior studies are thus more difficult to use in practical settings. We show how our approach can address this limitation by avoiding the use of this information during both testing and training.
Christophe Gravier
Professor of Computer Science, Head of Télécom Saint-Etienne
Scientific Coordinator of the Diké Project