+1 paper accepted to IDA 2023: "An Investigation of Structures Responsible for Gender Bias in BERT and DistilBERT"
TL;DR We offer empirical insights into bias investigation within the inner layers and heads of BERT and compare these findings with results obtained from DistilBERT.
Link for the paper : https://link.springer.com/chapter/10.1007/978-3-031-30047-9_20.
The introduction of large Pre-trained Language Models (PLM) has marked an important paradigm shift in Natural Language Processing.It leads to unprecedented progress in tasks such as machine translation, document classification, and multitask text generation. The strength of these approaches lies in their ability to produce contextual representations. They have been initially based on Recurrent Neural Networks (RNN) and they have gradually integrated the Transformers model as is the case for GPT3 or BERT, for example.
Compared to RNNs, Transformers can be parallelized, which opens the way, on one hand, to the use of ever-increasing training corpus (for example, GPT3 is trained on 45TB of data - almost the entire public web), and on the other hand, to the design of increasingly complex architectures (e.g., BERT large comprises 345 million parameters, BERT base 110 million). In a nutshell, Transformers are founded on three key innovations: positional encoding, scaled dot product attention, and multi-head attention.
As a result of a combination of all these elements, Transformers can learn an internal understanding of language automatically from the data. Despite their good performance on many different tasks, the use of these models in so-called sensitive applications or areas raised concerns over the past couple of years. Indeed, when decisions have an impact on individuals, for example in the medical and legal domains or human resources, it becomes crucial to study the fairness of these models. The core definition of fairness is still a hotly debated topic in the scientific community.
In our work, we adopt the following commonly accepted definition: fairness refers to the absence of any prejudice or favoritism towards an individual or a group based on their intrinsic or acquired traits. In machine learning, we assume that unfairness is the result of biased predictions (prejudice or favoritism), which are defined as elements that conduct a model to treat groups of individuals conditionally on some particular protected attributes, such as gender, race, or sexual orientation.
As an example, in human resources, the NLP-based recruitment task consists in analyzing and then selecting the relevant candidates. A lack of diversity inherent to the data, for instance, a corpus containing a large majority of male profiles (i.e. sample bias), will cause the model to maintain and accentuate a gender bias. When handling simple linear models trained on reasonable size corpora, creating safeguards to avoid this type of bias is conceivable.With PLM, the characteristics that allow them to perform so well are numerous: the size of their training corpus, the number of parameters, and their ability to infer a fine-grained semantic from the data. However, they are also what make it difficult to prevent them from encoding societal biases.
Conclusion and Discussion of Results
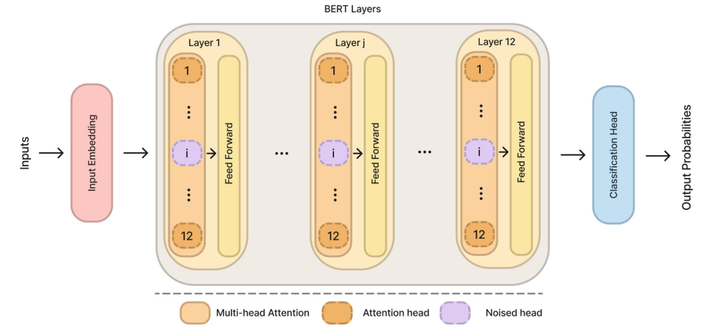
In this paper we investigate the implication of inner elements of BERT-based models’ architecture in bias encoding through empirical experiments on the Transformers’ layers and attention heads.
We also study the attention carried by the Investigation Gender Bias in BERT and DistilBERT “CLS” token to the words of the sequence, specifically the pronouns ‘he’ and ‘she’, but also to the ones receiving the most attention from the aforesaid token, in an attempt to understand what the model was focusing on; this study did not lead us to any convincing results.Similarly, investigating the JS divergence and SVCCA distance between different layers (e.g. the 1 and 2) was not conclusive, we suspect it might since layers specialize on different aspects of the input text.To summarize, we show that gender bias is not encoded in a specific layer or head.
We also demonstrate that the distilled version of BERT, DistilBERT, is more robust to double imbalance of classes and sensitive groups than the original model.Even more specifically, we observe that the representations generated by the attention heads in such a context are more homogeneous for DistilBERT than for BERT in which some attention heads will be fair while others are very unfair.
Thus, we advise giving special care to such patterns in the data but do not recommend ablating the heads producing more unfair representations since it could seriously harm the performance of the model.
Finally, we recommend DistilBERT to the practitioner using datasets containing underrepresented classes with a high imbalance between sensitive groups, while cautiously evaluating class independently, using the protocol that we propose in this paper.
Christophe Gravier
Professor of Computer Science, Head of Télécom Saint-Etienne
Scientific Coordinator of the Diké Project