 Image credit: Unsplash
Image credit: UnsplashAbstract
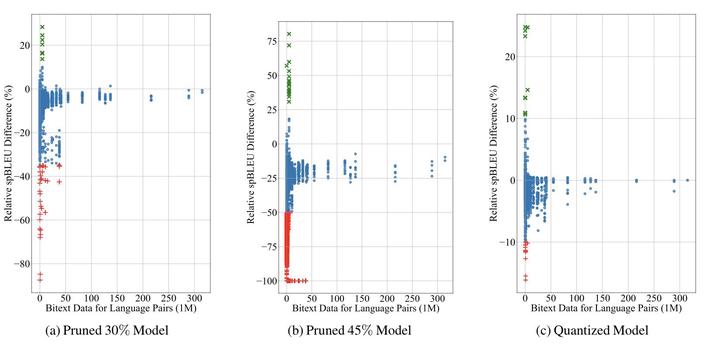
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
Supplementary notes can be added here, including code and math.